Background: LINQS Hackweek
Recently, my advisor decided to have our lab do a hackweek. You can read more about it here, but essentially a lot of us paused our research for 1 week and tried to build random things instead. One goal was for us to learn about the new tools out there that are accelerating learning and lowering the barriers to building.
The problem – messy fab notes
My friend Alex Hwang and I decided to try to build a nanofabrication copilot. The problem we wanted to address is our lab’s searchable-knowledge problem, specifically related to nanofabrication. We have about a decade’s worth of notes taken by ~40 students, and everyone’s notes are messy. Essentially, we have a dirty data bottleneck. Even worse is the fact that the notes are labeled by obscure project names and acronyms. This makes it hard for new students who might have simple fab questions, such as “How do you spin SPR-3612?” or “What is the expected ICP power on this tool?” and so on. This also makes it hard for more experienced students who want to learn from other people’s notes. For example, I might want to ask “Has anyone used a silica hard mask to do deep lithium niobate etches? If so, what are the failure modes?” Importantly, the answers we are looking for are very specific to our lab because our fab processes are very unique our cleanroom tools and our materials.
Because of this specificity, we ultimately decided to use Retrieval-Augmented Generation (RAG). RAG is a technique that grounds LLMs in external, factual knowledge. Instead of relying solely on the information an LLM memorized during training, RAG dynamically fetches relevant data from a designated knowledge base to help the model answer a specific query. I like the analogy of an LLM as a librarian. Without RAG, the librarian answers questions (about our fab notes) based solely on their memory, which is training data from the internet. With RAG, the librarian quickly reads our fab notes, augments their knowledge, and then answers our question.
Let me first provide a high-level summary of what we did. I’ll provide details in the sections below.
- Sort messy notes into schemas: We took everyone’s messy fab notes, removed the images, and then had an LLM sort chunks of text into schemas, which are basically different fab steps (spinning, etching, lithography etc.).
- Turn schemas into sentences: Once we had these schemas, we had an LLM convert them into natural language sentences.
- Embedding and retrieving: We embedded these sentences into a database.
- Chatting: When a user prompts our chatbot, we searched this database to find the most relevant sentences. Then we combined the user prompt, the relevant sentences, and a system prompt to an LLM to respond to the user.
Step 1: Sort messy notes to schemas
The schemas we defined here were essential fab steps (like spinning or etching). We defined about 10 schemas that we felt would encompass most people’s fab. Here are a few examples of schemas that we defined:
1
2
3
4
5
6
7
8
class SpinCoating(FabStepCommon):
step_type: Literal["spin_coating"] = "spin_coating"
material: Optional[str] = Field(None, description="Material spun")
speed_rpm: Optional[float] = Field(None, description="Spin speed in RPM")
acceleration_rpm_s: Optional[float] = Field(None, description="Acceleration in RPM/s")
duration_s: Optional[float] = Field(None, description="Duration in seconds")
bake_temp_c: Optional[float] = Field(None, description="Bake temp in C")
bake_duration_s: Optional[float] = Field(None, description="Bake duration in seconds")
1
2
3
4
5
6
7
8
9
class Deposition(FabStepCommon):
step_type: Literal["deposition"] = "deposition"
method: Optional[str] = Field(None, description="Evaporation, Sputtering, etc.")
tool: Optional[str] = Field(None, description="Tool name")
material: Optional[str] = Field(None, description="Material deposited")
thickness_target_nm: Optional[float] = Field(None, description="Target thickness")
rate: Optional[str] = Field(None, description="Deposition rate")
pressure: Optional[str] = Field(None, description="Chamber pressure")
gas_flow: Optional[str] = Field(None, description="Gas flows")
Some people’s fab notes become really long and exceeded a typical LLMs context window (i.e. it was too much text). So in this step, we would take someone’s notes and chunk the text, then prompt an LLM to sort that chunk of text into schemas. But because people will typically provide a short summary about their fab at the start of the doc, we wanted to somehow capture that context. To do so, we also defined a “global context” schema and first had the LLM fill that out by looking at the start of each document. Here was our system prompt for this task:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
system_prompt = f"""
You are an intelligent assistant categorizing scientific process logs.
Your goal is to extract the Global Context for the provided file.
INPUT:
- Filename: {filename}
- Content Preview (First 3000 chars): "{text_preview}..."
INSTRUCTIONS:
1. Identify the **Project Name** (often in headers or filename).
2. Identify the **Material Stack** if mentioned (e.g., "LN on Si", "Aluminum on SiO2").
3. Identify **People's Initials** involved (e.g., "TM", "ES", "WTJ").
4. Identify the **Rough Date/Year** of the work.
Output strictly valid JSON matching the schema below.
Target Schema:
{schema_json}
"""
We then took this global context and each chunk of text and had the LLM sort it into schemas. Here was the system prompt:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
system_prompt = f"""
You are an expert process engineer. Analyze the provided fabrication log segment.
Extract distinct operations (steps) into a JSON object.
GLOBAL CONTEXT for this file:
{global_context}
INSTRUCTIONS:
1. Extract specific process parameters matching the schema.
2. Fill "Common Attributes":
- **Person/Project**: Infer from text or use Global Context.
- **Material Stack**: Describe the full stack (e.g., "500nm LN on SiO2 on Si"). Use Global Context if the step doesn't specify.
- **Date**: Look for headers (e.g., "# Dec 3").
3. Use 'observations' for qualitative notes.
4. Set 'document_name' to "{filename}".
5. IGNORE 'preceding_step_summary' and 'following_step_summary' (filled later).
Output strictly valid JSON with root key "fab_steps".
Target Schema:
{schema_json}
"""
The output of all of this were sorted schemes that looked like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
{
"step_type": "metrology",
"document_name": "220409_PADL01_Process_Notes.md",
"person": "Takuma",
"date": "2022-04-19",
"method": "Filmetrics",
"tool": "Filmetrics",
"feature_measured": "Resist thickness",
"measurement_result": "PMMA: 327.43 nm \u00b1 56.73 nm; MMA: 534.14 nm \u00b1 67.81 nm; GOF ~0.94787",
"observations": "Best practice is to measure MMA thickness then PMMA thickness but not have the tool fit the MMA thickness.",
"preceding_step_summary": "spin_coating by Takuma",
"following_step_summary": "lithography by Takuma"
},
Step 2: Turn schemas into sentences
Ultimately, what gets embedded into our database needs to be natural language sentences. So we needed to convert the schemas (which are python classes) into sentences. Because we tried to have the schemes contain as much information as possible, we didn’t use an LLM here. We just had a simple python function that stuck together the strings in the schemas and made them sentences.
Step 3: Embedding and retrieving
We used the BGE-M3 model to do our embeddings. Embedding basically takes natural language sentences and turns them into vectors that the LLM can process. Once the embedding was done, we had a database that the LLM would retrieve knowledge from. For retrieval, we implemented hybrid search. At its core, hybrid search in RAG is the combination of two different search techniques—traditional keyword search and modern semantic search—to retrieve the most relevant information for an LLM to use. Keyword search works by looking for exact word matches and is good for finding very specific names and acronyms but is bad for looking for synonyms. Semantic search does well with context and synonyms and intent but fails with very obscure names. In our case, keyword search helps with identifying obscure names, like “PT-DSE” for “PlasmaTherm Deep Silicon Etcher” and so on. But we also need semantic search because we want words like “rinse” and “spray” to be searched together.
Here is an example of the embeddings that were returned when I searched our database with “PT-DSE”
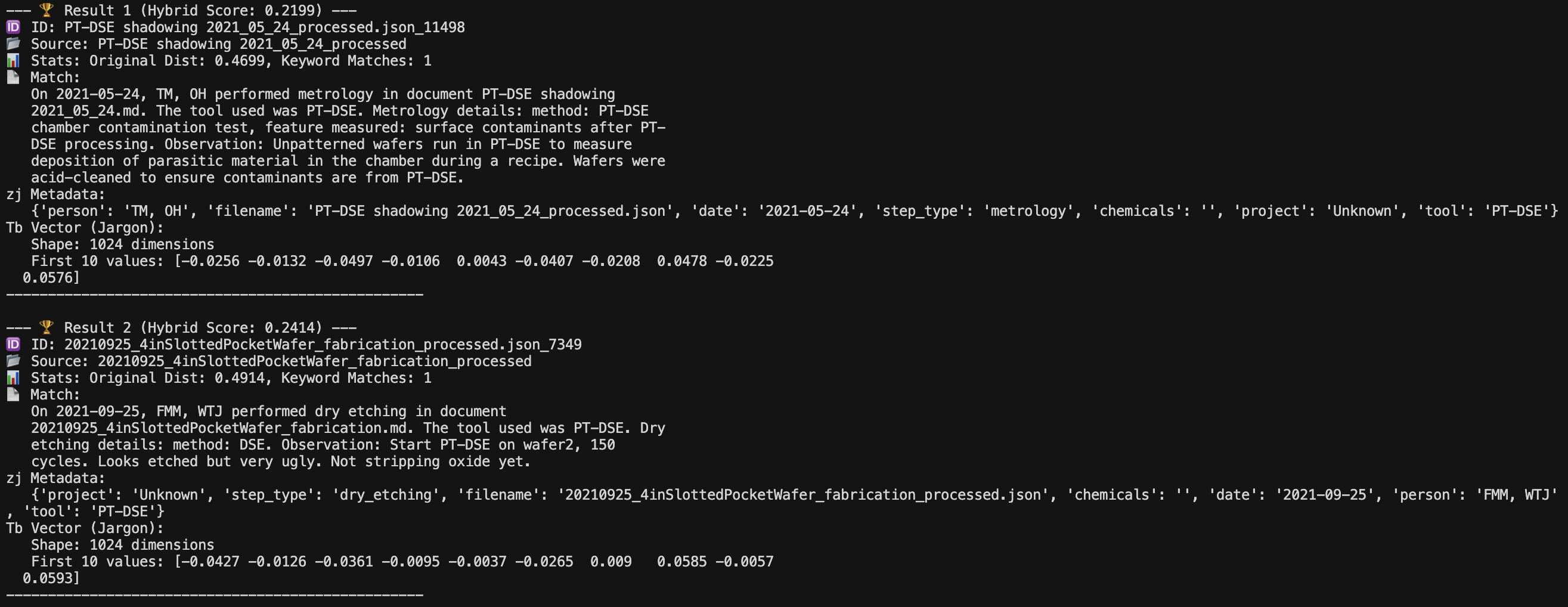 Figure 1: Results from hybrid search on our database.
Figure 1: Results from hybrid search on our database.
Step 4: Chatting
When a user prompts our chatbot, we the took highest-ranked embeddings from hybrid search and then combined it with a system prompt to our LLM. Here was the system prompt:
1
2
3
4
5
6
7
8
9
10
11
12
You are an expert fabrication process engineer who works on a team at a university.
You are tasked with answering user questions and providing advice to the user based on previous fabrication logs generated by the team.
The question will be provided to you as a natural language question.
In order to answer the user's question, you are given context from fabrication logs and associated references.
Rules:
1. Base your answer ONLY on the provided context.
2. If the context doesn't contain the answer, say "I couldn't find that information in the logs."
3. Cite your sources using the [Ref X] tags provided in the context.
4. Be technical and be concise.
5. If there is a specific project name or document associated with the context, explicitly state it.
And finally, here are some examples of chats! I am only showing the summary that the LLM provided. With each answer, it also provides its actual references, which is important if the user want to read further.
What parameters should I use to dice silicon?
The logs provide detailed parameters for dicing silicon using various tools and recipes. Here are the recommended parameters:
1. **Blade Type**:
- Use a **hub blade** such as **eszakiel_220614** ([Fab Log Ref 1]) or **oliver_210620** ([Fab Log Ref 6]).
- Alternatively, use a **resin blade** like **jfherrm 2204** for specific recipes ([Fab Log Ref 5]).
2. **Spindle Speed**:
- Typical spindle speeds range from **20,000 RPM** ([Fab Log Ref 5]) to **30,000 RPM** ([Fab Log Ref 3, Ref 7]).
3. **Feed Speed**:
- Common feed speeds include:
- **0.5 mm/s** for controlled dicing ([Fab Log Ref 3, Ref 5, Ref 6]).
- **2.0 mm/s** for faster dicing ([Fab Log Ref 7]).
4. **Blade Height**:
- Blade height is typically set to **0.05 mm** ([Fab Log Ref 3, Ref 7]).
5. **Water Flow**:
- Water flow is set to **0.5 L/min** for both channels ([Fab Log Ref 1, Ref 3]).
6. **Alignment**:
- Align theta to the flat edge of the silicon wafer for precision ([Fab Log Ref 2]).
- Use position readout for accurate alignment ([Fab Log Ref 5]).
7. **Kerf Width**:
- Kerf widths vary depending on the blade and recipe, e.g., **260 µm** ([Fab Log Ref 5]) or **107.1 µm** ([Fab Log Ref 7]).
8. **Recipe**:
- Use recipes such as **esz_LN-Si** ([Fab Log Ref 1, Ref 4]) or **kmultani_5x5** ([Fab Log Ref 5]) for silicon dicing.How do I prevent my chips from flying off during dicing?
To prevent chips from flying off during dicing, the logs suggest several strategies:
1. **Tape Adhesion**:
- Use **stickier tape** to improve adhesion during dicing. For example, in the **250305_lowfats05_fab_doc.md**, chip loss was attributed to insufficient tape adhesion, and the suggestion was made to use stickier tape ([Fab Log Ref 4]).
- Ensure proper tape pressing using tools like a **dark gray roller** to minimize chip movement, as noted in the **FLXM02 _ lowfATS01 Process Notes.md** ([Fab Log Ref 6]).
2. **Dicing Parameters**:
- Reduce **cut depth** to avoid excessive stress on the chips. In the **250305_lowfats05_fab_doc.md**, chip loss occurred at various cut depths, and decreasing the cut depth was recommended ([Fab Log Ref 4]).
- Use a **low feed rate** (e.g., **0.5 mm/s**) and controlled **spindle speed** (e.g., **30,000 RPM**) to minimize vibrations and stress during dicing ([Fab Log Ref 6]).
- Maintain **water flow** at **0.5 L/min** to cool the blade and reduce chip movement ([Fab Log Ref 6]).
3. **Sandwich Tape Method**:
- Apply a second layer of tape (sandwich method) after the first set of cuts to secure the chips before performing the second set of cuts. This method was successfully used in the **FLXM02 _ lowfATS01 Process Notes.md** ([Fab Log Ref 6]).
- Avoid pressing too hard on the tape sandwich near the chips to prevent shifts ([Fab Log Ref 6]).
4. **Alignment**:
- Proper alignment of the chips and tape is critical. For example, in the **250305_lowfats05_fab_doc.md**, chip orientation was carefully adjusted to minimize loss ([Fab Log Ref 7]).What are the considerations for fracturing Josephson junctions in BEAMER?
The logs provide detailed considerations for fracturing Josephson junctions in BEAMER:
1. **Manual Field Placement**:
- Manual field placement in BEAMER is critical to avoid overlapping fields, which can cause unpredictable assignment of polygons. Overlapping fields lead to errors in the traversal path and can compromise the integrity of the junctions ([Fab Log Ref 1]).
2. **Traversal Path Verification**:
- After fracturing, verify that the traversal path writes one entire SQUID array before moving to another. This ensures efficient traversal and minimizes errors during exposure ([Fab Log Ref 1]).
3. **Fracturing Settings**:
- **Conventional fracturing**: Used to maintain predictable field boundaries.
- **No compaction**: Ensures that the fractured geometry does not compress or distort the design.
- **Shot pitch fracturing**: None, to avoid introducing additional artifacts.
- **Dose to class**: Used to optimize exposure doses for different regions.
- **Multipass**: None, to simplify the exposure process.
- **Extent**: Auto, to allow BEAMER to automatically determine the field extent ([Fab Log Ref 1]).
4. **Critical Observations**:
- Fracturing errors can result in alignment issues and incomplete resist removal, leading to scum in the junction critical region and SQUID loop. Longer develop times and ghost lining may help mitigate scum ([Fab Log Ref 4]).How do I strip my HSQ spin if it goes wrong?
To strip HSQ after a failed spin, the logs suggest using **25% TMAH (Tetramethylammonium Hydroxide)** as the primary method:
1. **Wet Strip with TMAH**:
- In the **LNOSM2 Process Notes**, HSQ was stripped using **25% TMAH** after a failed spin. This method was used to clean the chip and prepare it for re-spinning ([Fab Log Ref 1, Ref 3]).
- TMAH effectively removes HSQ without damaging the chip surface, as noted in multiple instances ([Fab Log Ref 1, Ref 3]).
- This approach was specifically used when the HSQ spin did not spread properly or failed to adhere uniformly ([Fab Log Ref 3]).
2. **Observation**:
- Stripping HSQ with TMAH was necessary to remove the failed spin and allow for re-spinning ([Fab Log Ref 1, Ref 3]).How can I etch 500 um of silicon?
To etch **500 µm of silicon**, the logs suggest using **Deep Silicon Etch (DSE)** methods, such as DRIE or PT-DSE. Here are the relevant parameters and observations:
1. **Etch Method**:
- **Deep Silicon Etch (DSE)** is the preferred method for etching large depths of silicon. For example:
- In the **20210915 BBMMW02 fabrication notes**, 250 µm of silicon was etched using **365 cycles** with an etch rate of **0.685 µm/cycle** ([Fab Log Ref 2]).
- In the same fabrication notes, another DSE process achieved an etch rate of **0.83 µm/cycle**, requiring **362 cycles** for a 300 µm etch ([Fab Log Ref 5]).
- To achieve 500 µm, you would need approximately **600–730 cycles**, depending on the etch rate.
2. **Tool and Recipe**:
- Use tools like **PT-DSE** or **FAT EBTr** for silicon etching.
- Recipes such as **rvanlaer** or **LINQS** are commonly used for DSE ([Fab Log Ref 4, Ref 5]).
3. **Etch Parameters**:
- **Etch Rate**: Typical etch rates range from **0.685 µm/cycle** to **0.83 µm/cycle** ([Fab Log Ref 2, Ref 5]).
- **Cycles**: For 500 µm, calculate the number of cycles based on the etch rate. For example:
- At **0.685 µm/cycle**, you would need ~730 cycles.
- At **0.83 µm/cycle**, you would need ~600 cycles.
- **Power**: In the **230906_HIR01_Process_Notes**, power settings were **1200 W** for etching and **0 W** for cooling ([Fab Log Ref 3]).
- **Cooling**: Include cooling steps (e.g., **1 min cooling after every 30 loops**) to prevent overheating and maintain uniform etching ([Fab Log Ref 3]).
4. **Observations**:
- Ensure proper wafer adhesion to prevent the wafer from falling off during the etch. For example, in the **20210915 BBMMW02 fabrication notes**, kapton tape was used to secure the wafer ([Fab Log Ref 2]).
- Monitor He pressure and chamber conditions to avoid process errors ([Fab Log Ref 7]).Next steps
Towards the end of hackweek, Alex and I started to implement user feedback. We gave users the option of correcting a response from the LLM, and their response was embedded into a separate database that we also retrieved knowledge from. We updated the system prompt to:
You are an expert fabrication process engineer who works on a team.
You are tasked with answering user questions and providing advice to the user based on: (1) previous fabrication logs generated by the team, and (2) previous discussions with team members.
The question will be provided to you as a natural language question.
In order to answer the user's question, you are given context from: (1) previous fabrication logs and associated references, and (2) previous discussions with team members.
Rules:
1. Base your answer ONLY on the provided context.
2. Your answer should explicitly differentiate between context from previous fabrication logs and context from previous discussions with team members.
3. Your answer should be organized as follows: (1) summarize your answer from previous fabrication logs, (2) summarize your answer from previous discussions, (3) cite the previous fabrication logs, (4) cite the previous discussions.
4. Cite your fabrication log sources using the [Ref X] tags provided in the context
5. Cite your discussion sources using the [Ref X] tags provided in the context
6. If the context doesn't contain the answer, say "I couldn't find that information in the logs or from previous discussions with other team members.”
7. Be technical and be concise.
8. If there is a specific project name or document associated with the fab context, explicitly state
9. If there is a specific person or name associated with the discussion context, explicitly state it.And here’s an example of a response where the LLM answered based on previous fab notes and also answered based on previous user feedback. The questions was “How do I strip crosslinked resist from my chip?”
### Summary from Previous Fabrication Logs:
To strip crosslinked resist, the fabrication logs suggest the following methods:
1. **Nanostrip Soak**:
- In the **240216_single_mask_circuit_development.md**, crosslinked resist was successfully removed by soaking the chip in **Nanostrip at 35°C for 1200 seconds (20 minutes)**. This method was observed to remove all crosslinked resist without affecting Nb layers ([Fab Log Ref 4]).
- Note: Nanostrip may attack sensitive metals like aluminum, so caution is required ([Fab Log Ref 4]).
2. **Hot NMP**:
- In the **LN_ Releasing Structures in PT-DSE.md**, NMP was heated to **80°C** for 60 minutes to strip resist. This method is less aggressive and can be used for crosslinked resist ([Fab Log Ref 3]).
- Followed by IPA spray and soak to clean residual resist ([Fab Log Ref 3]).
3. **Solvent Cleaning**:
- Acetone and IPA sprays were used in **240216_single_mask_circuit_development.md**, but these methods were insufficient for removing crosslinked resist ([Fab Log Ref 2, Ref 6]).
### Summary from Previous Discussions:
From discussions with Takuma Makihara:
1. **Nanostrip**:
- Nanostrip at **35°C for 20 minutes** is effective for removing crosslinked resist but may attack sensitive metals like aluminum ([Discussion Ref 1, Ref 2]).
2. **Hot NMP**:
- **Hot NMP (heated to 80°C)** should be attempted first for crosslinked resist. It is less aggressive and safer for sensitive materials like aluminum ([Discussion Ref 1, Ref 2]).
3. **Piranha Solution**:
- For a more aggressive clean, **Piranha solution** can be used, but it has the same chemistry as Nanostrip and will also attack sensitive metals like aluminum. Use with caution ([Discussion Ref 1, Ref 2]).Another thing that I want to learn more about is benchmarking. Throughout the week, Alex and I would tweak things (like chunk size, schemas, model choice, system prompt etc.) and it was often hard to tell how much the answers improved. I would want to use a more concrete figure of merit that we could optimize against, like a quality factor.